
大家好,又到了美好的周末
在Day 8、Day 9 時,我們已經透過 Data Collection services – AWS Appflow 擷取 Google Analytics 資料並將原始資料存放至 AWS 的 S3 Bucket,並發現 Google Analytics 檔案為多行的 JSON 格式,無法進行後續資料分析以及視覺化,而今天我們會來教學如何透過 AWS Lambda 服務來將此 JSON 格式文件轉換為 Apache Parquet 格式並將此處理過後的檔案存放在 AWS S3 Bucket,不僅大大加速查詢的結果以及儲存的費用。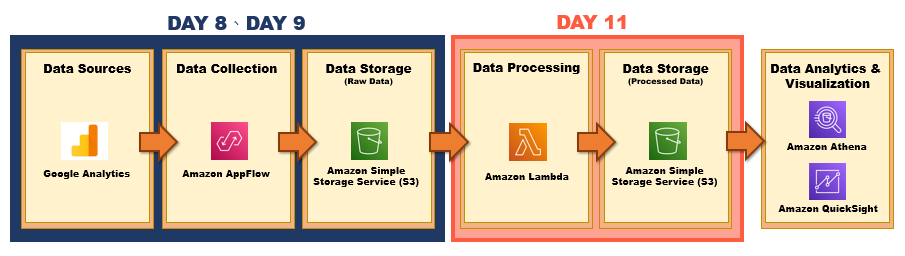
大致流程如下所示:

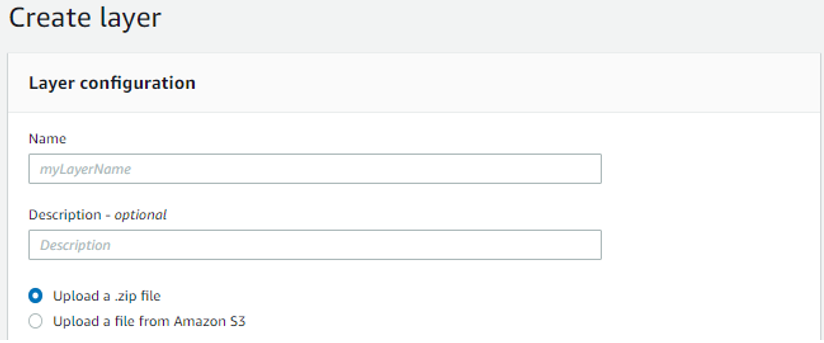
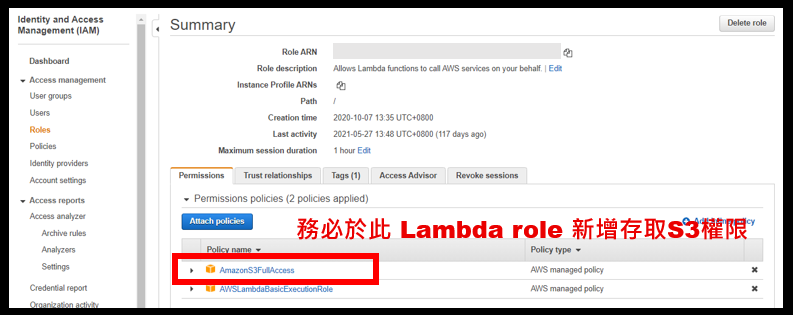
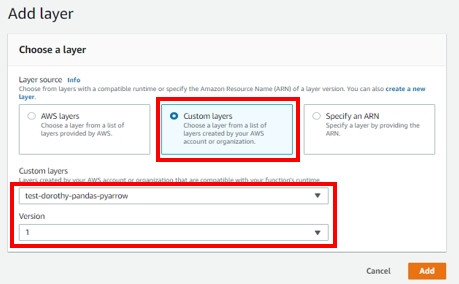
此實作我們是用 python 3.7 撰寫語法,程式碼中有包含部分模組是 Lambda 原生沒有的,這時我們就必須將這些模組檔案打包成 zip 檔,然後再上傳到 AWS
那這次實作,因為我們需要安裝 pandas 以及 pyarrow 套件,我在 AWS EC2 中安裝模組並進行打包,以下相關指令供大家參考:
#先更新所有套件
sudo yum update -y
#安裝Docker
sudo yum install docker -y
#啟用Docker
sudo service docker start
#安裝pip
sudo yum -y install python-pip
#創建資料夾,後續會將套件存放在此
mkdir python
#從docker hub載入python3.7.12的映像檔(映像檔可以詳[1])
sudo docker run -it --rm -v $(pwd)/python:/python python:3.7.12
#安裝pandas以及pyarrow套件
sudo pip install -t $(pwd)/python pandas==0.23.4 pyarrow==0.11.1
#將python資料夾壓成zip檔
sudo zip -r pandas-pyarrow.zip python
結果如下圖所示:
輸入 Function name 並設定 runtime 為 python 3.7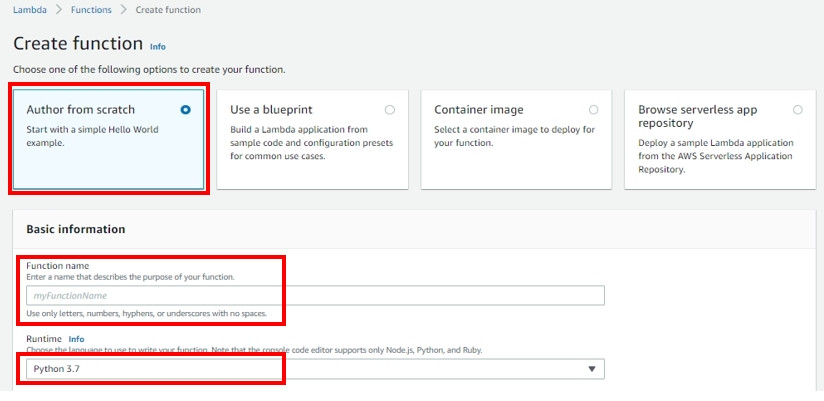

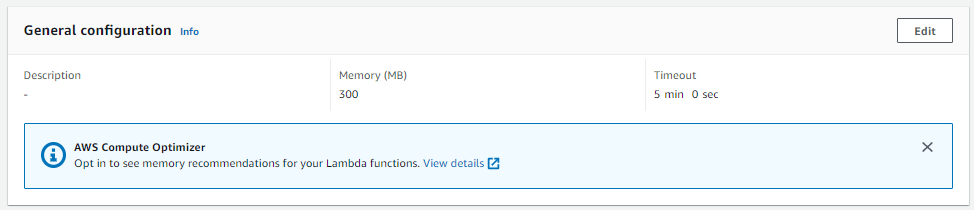
若 Lambda 運行過程中超過 Memory或 Time,Lambda就會發生 Fail 
強烈建議 Prefix 要填寫,若沒有填寫僅填寫 Bucket 名稱,那代表說只要此 Bucket 有新增資料,就會觸發 Lambda,可能會造成異常的費用產生跟錯誤~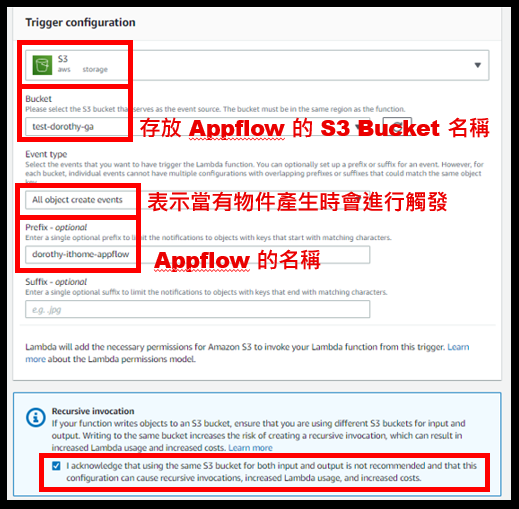
#匯入所需套件
import json
import urllib.parse
import pandas as pd
import boto3
from datetime import datetime as dt
def lambda_handler(event, context):
#讀取S3 Bucket名稱以及檔案名稱
bucket_name = event['Records'][0]['s3']['bucket']['name']
object_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
s3_client = boto3.client('s3')
#讀取原始資料
raw_object = s3_client.get_object(Bucket=bucket_name, Key=object_key)
raw_data = json.loads(raw_object['Body'].read().decode('utf-8'))
#擷取必要的原始資料並將其轉換名稱以及Parquet 格式
record_dates = [dt.strptime(r['dimensions'][0], '%Y%m%d') for r in raw_data['reports'][0]['data']['rows']]
deviceCategory= [r['dimensions'][1] for r in raw_data['reports'][0]['data']['rows']]
pageviews = [int(r['metrics'][0]['values'][0]) for r in raw_data['reports'][0]['data']['rows']]
df = pd.DataFrame({
'year': [r.year for r in record_dates],
'month': [r.month for r in record_dates],
'day': [r.day for r in record_dates],
'deviceCategory': deviceCategory,
' pageviews': pageviews
})
#將處理好的資料儲存至同一個S3 Bucket的另外一個ga-data資料夾中
output_file = dt.now().strftime('%Y%m%d%H%M%S')
output_path = '/tmp/{}.parquet'.format(output_file)
df.to_parquet(output_path)
s3_resource = boto3.resource('s3')
bucket = s3_resource.Bucket(bucket_name)
bucket.upload_file(output_path, 'ga-data/{}.parquet'.format(output_file))
設定完以上內容後~ 請重新執行 Appflow,那麼 AppFlow 會重新拉取 Google Analytics 資料並存放在 AWS S3 Bucket,這時因特定路徑有新的資料產生,就會觸發此 Lambda 自動將 Google Analytics JSON 檔案中提取必要的數據並將其轉換為 Parquet 格式,再將此 Parquet 檔案再上傳至 AWS S3 Bucket 中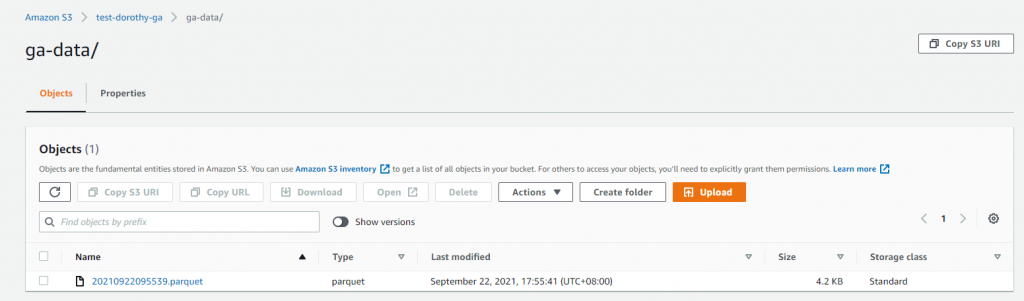
今天我們順利的把檔案轉成 Parquet 格式,明天我們就會開始進行資料分析以及視覺化的階段,那就明天見啦:)
如果有任何指點與建議,也歡迎留言交流,一起漫步在 Data on AWS 中。
參考&相關來源:
[1] dockerhub python
https://hub.docker.com/_/python

 iThome鐵人賽
iThome鐵人賽